论文笔记--Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
- 1. 文章简介
- 2. 文章概括
- 3 文章重点技术
- 3.1 Segment-Level Recurrence with State Reuse
- 3.2 相对位置编码
- 4. 文章亮点
- 5. 原文传送门
1. 文章简介
- 标题:Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
- 作者:Zihang Dai, Zhilin Yang, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov
- 日期:2019
- 期刊:arxiv preprint
2. 文章概括
传统的RNN常常面临梯度消失或爆炸的问题,LSTM的提出在一定程度上有所缓解,但实验表明LSTM只能有效利用200个左右上下文单词信息。Transformer的提出可以充分利用上下文的信息,但受限于输入的固定长度,一般为256,512等。Al-Fou提出的character-level的Transformer可以将输入分为不同的segment,但不同的segment之间没有交互:比如输入被划分为 s 1 , … , s L s_1, \dots, s_L s1,…,sL和 s L + 1 , … , s N s_{L+1}, \dots, s_N sL+1,…,sN两个片段,则模型无法利用到 t < L + 1 t<L+1 t<L+1的信息来预测 S L + 1 S_{L+1} SL+1,从而第二个片段开始位置的几个token则变得很难预测。
为了解决上述问题,文章提出了一种类似RNN的循环机制Transformer:Transformer-XL,可有效处理长文本输入。且文章提出了适应于Transformer-XL的位置编码方法:相对位置编码。实验表明,Transformer-XL在多个数据集上取得了SOTA结果。
3 文章重点技术
3.1 Segment-Level Recurrence with State Reuse
为了解决Context Fragmentation(基于segmentation的方法无法实现segmentation之间的交互)和fixed length(输入大小受限)的问题。文章将循环机制引入到Transformer架构。训练阶段,上一个文本片段(segment)的隐藏层状态被固定(不参与梯度更新)并缓存,在下一个片段中作为扩展的上下文使用。整体架构如下图所示:
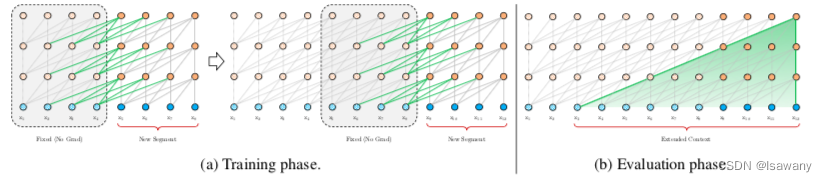
具体来说,令 s τ = [ x τ 1 , … , x τ L ] s_\tau = [x_{\tau_1}, \dots, x_{\tau_L}] sτ=[xτ1,…,xτL]为第 τ \tau τ个片段,其中 L L L为每个片段接收的最大输入长度。则在计算第 τ + 1 \tau + 1 τ+1个片段的第 n n n个隐藏层 h τ + 1 n h_{\tau + 1}^n hτ+1n时,我们首先通过当前片段和上一个片段的第 n − 1 n-1 n−1个片段的隐藏层得到候选隐藏层 h ~ τ + 1 n − 1 = S t o p G r a d i e n t ( h τ n − 1 ) + h τ + 1 n − 1 \tilde{h}_{\tau+1}^{n-1} = StopGradient(h_{\tau}^{n-1}) + h_{\tau + 1}^{n-1} h~τ+1n−1=StopGradient(hτn−1)+hτ+1n−1,然后通过候选隐藏层更新当前Transformer的Q, K ,V: q τ + 1 n , k τ + 1 n , v τ + 1 n = h τ + 1 n − 1 W q T , h ~ τ + 1 n − 1 W k T , h ~ τ + 1 n − 1 W v T q_{\tau+1}^n,k_{\tau+1}^n,v_{\tau+1}^n = h_{\tau + 1}^{n-1}W_q^T, \tilde{h}_{\tau+1}^{n-1} W_k^T, \tilde{h}_{\tau+1}^{n-1} W_v^T qτ+1n,kτ+1n,vτ+1n=hτ+1n−1WqT,h~τ+1n−1WkT,h~τ+1n−1WvT,注意到key和value向量由上下文和当前词共同确定,从而引入了上一个segment的信息,而query向量只有当前隐藏层确定。再由Q, K, V计算得到当前层的 h τ + 1 n h_{\tau+1}^n hτ+1n,即注意力分数。
上述方法可以有效解决长文本依赖问题,且不丢失上下文信息。此外在评估阶段模型无需重新计算前面片段的表征,从而速率更高。另一方面,我们可以很容易地使用前面多个segment的上下文信息,从而文本依赖不局限于前一个segment。
3.2 相对位置编码
注意到,按照上述分割方式传入到模型每个segment的位置编码均为从1 到 L L L,无法有效区分不同segment的信息。从而文章提出了relative positional encoding,即相对位置编码。具体地,文章预先定义了一个不可学习的位置编码矩阵(sinusoid) R ∈ R L × d \mathcal{R}\in\mathbb{R}^{L\times d} R∈RL×d。其中行 R i R_i Ri表示相对位置为 i i i的两个向量之间的位置编码向量,即当query和key之间距离为i时直接用 R i R_i Ri来作为其位置编码,和词向量嵌入进行拼接。
为了使用相对位置编码,文章对Transformer的注意力计算公式进行了优化。传统的Transformer计算方式为 Q T K = ( W Q ( E x + U ) ) T ( W K ( E x + U ) ) Q^TK = (W^Q(E_x + U))^T (W^K(E_x + U)) QTK=(WQ(Ex+U))T(WK(Ex+U)),其中 E x , U E_x, U Ex,U分别表示词向量和位置向量,则 q i q_i qi和 k j k_j kj之间的注意力分数为 A i , j a b s = E x i T W q T W k E x j + E x i T W q T U j + U i T W q T W k E x j + U i T W q T W k U j A_{i,j}^{abs} = E_{x_i}^TW_q^T W_kE_{x_j} + E_{x_i}^TW_q^T U_j + U_i^TW_q^T W_kE_{x_j} + U_i^TW_q^T W_kU_j Ai,jabs=ExiTWqTWkExj+ExiTWqTUj+UiTWqTWkExj+UiTWqTWkUj。我们将其优化为 A i , j r e l = E x i T W q T W k , E E x j + E x i T W k , R T R i − j + u T W q T W k , E E x j + v T W q T W k , R R i − j A_{i,j}^{rel} = E_{x_i}^TW_q^T W_{k, E}E_{x_j} + E_{x_i}^TW_{k, R}^T R_{i-j} + u^TW_q^T W_{k, E}E_{x_j} + v^TW_q^T W_{k, R}R_{i-j} Ai,jrel=ExiTWqTWk,EExj+ExiTWk,RTRi−j+uTWqTWk,EExj+vTWqTWk,RRi−j,上述四项分别代表1)基于内容的寻址 2)内容有关的位置偏差 3)整体内容偏差 4)整体位置偏差。
4. 文章亮点
文章有效解决了NLP中长文本依赖捕获问题,且有效避免了context-fragmenation问题。多个数值实验表明,文章在长文本、短文本的下游任务中表现出色,且相比于RNN-LMs在评估过程中提升了效率,可作为未来NLP长文本任务中的一项可靠工具。
5. 原文传送门
Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context