論文筆記--Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
論文筆記--Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
- 1. 文章簡介
- 2. 文章概括
- 3 文章重點技術
- 3.1 Segment-Level Recurrence with State Reuse
- 3.2 相對位置編碼
- 4. 文章亮點
- 5. 原文傳送門
1. 文章簡介
- 標題:Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
- 作者:Zihang Dai, Zhilin Yang, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov
- 日期:2019
- 期刊:arxiv preprint
2. 文章概括
??傳統的RNN常常面臨梯度消失或爆炸的問題,LSTM的提出在一定程度上有所緩解,但實驗表明LSTM只能有效利用200個左右上下文單詞信息。Transformer的提出可以充分利用上下文的信息,但受限于輸入的固定長度,一般為256,512等。Al-Fou提出的character-level的Transformer可以將輸入分為不同的segment,但不同的segment之間沒有交互:比如輸入被劃分為 s 1 , … , s L s_1, \dots, s_L s1?,…,sL?和 s L + 1 , … , s N s_{L+1}, \dots, s_N sL+1?,…,sN?兩個片段,則模型無法利用到 t < L + 1 t<L+1 t<L+1的信息來預測 S L + 1 S_{L+1} SL+1?,從而第二個片段開始位置的幾個token則變得很難預測。
??為了解決上述問題,文章提出了一種類似RNN的循環機制Transformer:Transformer-XL,可有效處理長文本輸入。且文章提出了適應于Transformer-XL的位置編碼方法:相對位置編碼。實驗表明,Transformer-XL在多個數據集上取得了SOTA結果。
3 文章重點技術
3.1 Segment-Level Recurrence with State Reuse
??為了解決Context Fragmentation(基于segmentation的方法無法實現segmentation之間的交互)和fixed length(輸入大小受限)的問題。文章將循環機制引入到Transformer架構。訓練階段,上一個文本片段(segment)的隱藏層狀態被固定(不參與梯度更新)并緩存,在下一個片段中作為擴展的上下文使用。整體架構如下圖所示:
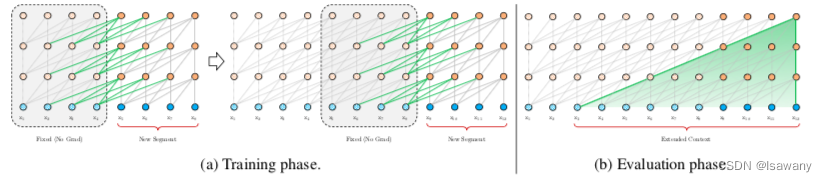
??具體來說,令 s τ = [ x τ 1 , … , x τ L ] s_\tau = [x_{\tau_1}, \dots, x_{\tau_L}] sτ?=[xτ1??,…,xτL??]為第 τ \tau τ個片段,其中 L L L為每個片段接收的最大輸入長度。則在計算第 τ + 1 \tau + 1 τ+1個片段的第 n n n個隱藏層 h τ + 1 n h_{\tau + 1}^n hτ+1n?時,我們首先通過當前片段和上一個片段的第 n ? 1 n-1 n?1個片段的隱藏層得到候選隱藏層 h ~ τ + 1 n ? 1 = S t o p G r a d i e n t ( h τ n ? 1 ) + h τ + 1 n ? 1 \tilde{h}_{\tau+1}^{n-1} = StopGradient(h_{\tau}^{n-1}) + h_{\tau + 1}^{n-1} h~τ+1n?1?=StopGradient(hτn?1?)+hτ+1n?1?,然后通過候選隱藏層更新當前Transformer的Q, K ,V: q τ + 1 n , k τ + 1 n , v τ + 1 n = h τ + 1 n ? 1 W q T , h ~ τ + 1 n ? 1 W k T , h ~ τ + 1 n ? 1 W v T q_{\tau+1}^n,k_{\tau+1}^n,v_{\tau+1}^n = h_{\tau + 1}^{n-1}W_q^T, \tilde{h}_{\tau+1}^{n-1} W_k^T, \tilde{h}_{\tau+1}^{n-1} W_v^T qτ+1n?,kτ+1n?,vτ+1n?=hτ+1n?1?WqT?,h~τ+1n?1?WkT?,h~τ+1n?1?WvT?,注意到key和value向量由上下文和當前詞共同確定,從而引入了上一個segment的信息,而query向量只有當前隱藏層確定。再由Q, K, V計算得到當前層的 h τ + 1 n h_{\tau+1}^n hτ+1n?,即注意力分數。
??上述方法可以有效解決長文本依賴問題,且不丟失上下文信息。此外在評估階段模型無需重新計算前面片段的表征,從而速率更高。另一方面,我們可以很容易地使用前面多個segment的上下文信息,從而文本依賴不局限于前一個segment。
3.2 相對位置編碼
??注意到,按照上述分割方式傳入到模型每個segment的位置編碼均為從1 到 L L L,無法有效區分不同segment的信息。從而文章提出了relative positional encoding,即相對位置編碼。具體地,文章預先定義了一個不可學習的位置編碼矩陣(sinusoid) R ∈ R L × d \mathcal{R}\in\mathbb{R}^{L\times d} R∈RL×d。其中行 R i R_i Ri?表示相對位置為 i i i的兩個向量之間的位置編碼向量,即當query和key之間距離為i時直接用 R i R_i Ri?來作為其位置編碼,和詞向量嵌入進行拼接。
??為了使用相對位置編碼,文章對Transformer的注意力計算公式進行了優化。傳統的Transformer計算方式為 Q T K = ( W Q ( E x + U ) ) T ( W K ( E x + U ) ) Q^TK = (W^Q(E_x + U))^T (W^K(E_x + U)) QTK=(WQ(Ex?+U))T(WK(Ex?+U)),其中 E x , U E_x, U Ex?,U分別表示詞向量和位置向量,則 q i q_i qi?和 k j k_j kj?之間的注意力分數為 A i , j a b s = E x i T W q T W k E x j + E x i T W q T U j + U i T W q T W k E x j + U i T W q T W k U j A_{i,j}^{abs} = E_{x_i}^TW_q^T W_kE_{x_j} + E_{x_i}^TW_q^T U_j + U_i^TW_q^T W_kE_{x_j} + U_i^TW_q^T W_kU_j Ai,jabs?=Exi?T?WqT?Wk?Exj??+Exi?T?WqT?Uj?+UiT?WqT?Wk?Exj??+UiT?WqT?Wk?Uj?。我們將其優化為 A i , j r e l = E x i T W q T W k , E E x j + E x i T W k , R T R i ? j + u T W q T W k , E E x j + v T W q T W k , R R i ? j A_{i,j}^{rel} = E_{x_i}^TW_q^T W_{k, E}E_{x_j} + E_{x_i}^TW_{k, R}^T R_{i-j} + u^TW_q^T W_{k, E}E_{x_j} + v^TW_q^T W_{k, R}R_{i-j} Ai,jrel?=Exi?T?WqT?Wk,E?Exj??+Exi?T?Wk,RT?Ri?j?+uTWqT?Wk,E?Exj??+vTWqT?Wk,R?Ri?j?,上述四項分別代表1)基于內容的尋址 2)內容有關的位置偏差 3)整體內容偏差 4)整體位置偏差。
4. 文章亮點
??文章有效解決了NLP中長文本依賴捕獲問題,且有效避免了context-fragmenation問題。多個數值實驗表明,文章在長文本、短文本的下游任務中表現出色,且相比于RNN-LMs在評估過程中提升了效率,可作為未來NLP長文本任務中的一項可靠工具。
5. 原文傳送門
Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。如若轉載,請注明出處:https://dhexx.cn/hk/4628030.html
如若內容造成侵權/違法違規/事實不符,請聯系我的編程經驗分享網進行投訴反饋,一經查實,立即刪除!