0. CountVecorizer
是属于常见的特征数值计算类,是一个文本特征提取方法。
对于每一个训练文本,它只考虑每种词汇在该训练文本中出现的频率。
CountVectorizer会将文本中的词语转换为词频矩阵,它通过fit_transform函数计算各个词语出现的次数。
CountVectorizer(input='content', encoding='utf-8', decode_error='strict', strip_accents=None, lowercase=True, preprocessor=None, tokenizer=None, stop_words=None,
token_pattern='(?u)\b\w\w+\b', ngram_range=(1, 1), analyzer='word', max_df=1.0, min_df=1, max_features=None, vocabulary=None, binary=False, dtype=<class 'numpy.int64'>)
一般要设置的参数:
ngram_range:词组切分的长度范围
max_df:可以设置范围在[0.0 1.0]的float,这个参数的作用是作为一个阈值。当构造预料库的关键词集的时候,如果某个词的document frequence大于max_df,这个词不会被当作关键词。如果这个参数是float,则表示词出现的次数与语料库文档数的百分比,如果是int,则表示词出现的次数。
min_df:类似于max_df,不同之处在于如果某个词的document frequence小于min_df,则这个词不会被当作关键词
max_features:默认为None,可设为int,对所有关键词的term frequency进行降序排序,只取前max_features个作为关键词集合
一、one-hot编码
1.1 解决什么问题
1.2 思想和模型
1.3 优缺点
二、词袋模型
2.1、解决什么问题
2.2、思想和模型
2.3、优缺点
三、TF-IDF
3.1、解决什么问题
3.2、思想和模型
是一种用于信息检索与数据挖掘的加权技术,是一种统计方法,用以评估一个字词对于一个预料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
计算方法:
a. 词频(TF)= 某个词在文章中的出现次数/文章的总词数
b. 逆文档评率(IDF) = log(语料库的文档总数/包含该词的文档数+1)
c. TF-IDF = TF * IDF
可用于自动提取关键词,计算出文档的每个词的TF-IDF值,然后按降序排列,取排在最前面的几个词。
3.3、优缺点
四、NNLM(神经网络语言模型)
4.1、解决什么问题
词袋模型和TF-IDF模型没有考虑单词的上下文关系。一般认为,后面的单词与前几个单词是有关系的,而n-gram model由于计算空间太大,计算时间较长不实用,因此,提出了NNLM语言模型,它是通过前几个单词,来预测后一个单词来建立的模型结构。
4.2、思想和模型




模型的前向传播:
该模型结构分为映射层(输入层)、隐藏层、输出层(全连接层+softmax)
输入层(映射层):从one-hot映射到distribution represention,词的映射过程如下,


隐层:
输出层:全连接+softmax,输出的也是一个[v,1]的one-hot向量
4.3 总结
从n元模型到神经网络语言模型,明显神经网络语言模型更胜一筹。从深度学习方法在机器翻译领域获得突破后,深度学习技术在NLP上已经全面超过了传统的方法,可以预见的是,未来几年,传统的方法或将陆续退出舞台,或者与深度学习结合。
五、word2vec
5.1、解决什么问题
NNLM模型的projection layer计算量太大,提出的word2vec将它去掉,减少了计算量。
5.2、思想和模型
CBOW模型

定义loss function(一般为交叉熵代价函数),采用梯度下降法更新W和W'。训练完毕后,输入层的每个单词与矩阵W相乘得到的向量就是我们要的词向量(word embedding),这个矩阵也叫做look up table,也就是说,任何一个单词的one-hot乘以这个矩阵都将得到自己的词向量。
模型特点:
1)无隐层; 2) 使用双向上下文窗口[左,右]文本预测[中间]单词; 3)上下文词序无关; 4)输入层直接使用低稠密表示; 5)投影层简化为求和(平均)
5.2.2 什么是哈夫曼树:权值大的叶子,更靠近根节点
Huffman编码(最优二叉树)是一种用于无损数据压缩的编码算法。该方法通过一种变长编码表来对符号进行编码,而变长编码表是通过评估符号出现概率的方法得到,目标是出现概率搞高的符号使用较短的编码,出现概率低的符号则使用较长的编码。这种方式能有效降低编码之后的字符串的平均长度。
哈夫曼树就就是构建一个由字符(每个字符都是叶子节点)的出现概率作为权值,求最短长度问题的树。

Hierachical(层次) softmax:本质是把N分类问题变成log(N)次二分类
在进行最优化的求解过程中:从隐藏层到输出的softmax层的计算量很大,因为要计算所有词的softmax概率,再去找概率最大的值。softmax回归需要对语料库中每个词语都计算一遍输出概率并进行归一化,在几十万词汇量的语料上无疑巨大。

5.2.3 负例采样:本质是预测总体类别的一个子集
分层softmax在每次循环迭代过程中依然要处理大量节点上的更新运算,而负例采样只需要更新“输出向量”的一部分。
普通softmax的计算量太大就是因为它把词典汇总所有其他非目标词都当做负例了,而负采样的思想特别简单,就是每次按照一定概率随机采样一些词当做负例,从而就只需要计算这些负采样出来的负例了,那么概率公式便相应变为:
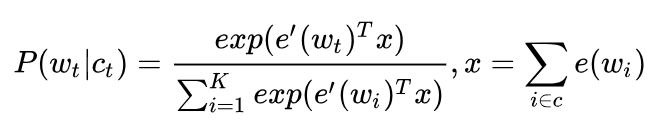
和普通softmax进行比较会发现,将原来的V分类问题变成了K分类问题,这便把词典大小对时间复杂度的影响变成了一个常数项,而改动又非常的微小。
5.2.4 skip-gram模型

可以看成是单个x->单个y模型的并联,cost function是单个cost function的累加(取log之后)
5.3、优缺点
1)对每个local context window单独训练,没有利用包含在global co-currence矩阵中的统计信息;
2)对多义词无法很好的表示和处理,因为使用了唯一的词向量;
六、Glove(Global vectors for word representation)
6.1 解决什么问题
利用全局的信息进行word embedding
模型目标:进行词的向量化表示,使得向量之间尽可能多地蕴含语义和语法的信息;
输入:语料库; 输出:词向量
6.2 模型及核心思想(为什么要这样设计结构)
6.2.1 GLOVE模型获得词向量的步骤可以分为两步:
1)构造共现矩阵X,其元素为Xi,j, Xi,j的意义为:在整个语料库中,单词i和单词j共同出现在一个窗口中的次数。
2)构造损失函数并训练模型
损失函数: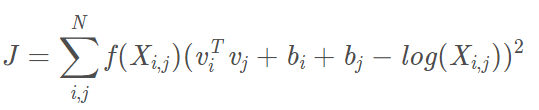
vi, vj是单词i和单词j的词向量,bi,bj是两个标量(模型偏差项),f是权重函数,N是词汇表的大小(共线矩阵维度是N*N)。可以看到,Glove没有使用神经网络的方法。
6.2.2 模型构建思路
思想:假设我们已经得到了词向量,如果我们用词向量vi,vj,vk通过某种函数计算ratioi,j,k,能够得到这样的规律的话(单词i,k相关,ratio趋近1,否则很小),就意味着我们词向量与共现矩阵具有很好的一致性,也就说明我们的词向量中蕴含了共现矩阵中所蕴含的信息。
找到词向量来模拟共线概率比值![]()


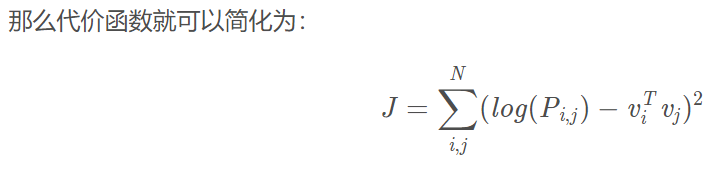



6.3 GLOVE和word2vec的区别
word2vec每次都用一个窗口中的信息更新词向量,但是Glove则是用了全局的信息(共现矩阵),也就是多个窗口进行更新。
-------------------------------------------------------------------------------------------------------
七、Doc2vec(也叫sentence embeddings/vec)
7.1 解决什么问题
有没有什么办法能够将一个句子,甚至一片短文也用一个向量来表示呢?答案是肯定的,构建一个句子向量的办法之一就是Doc2vec。它可以不用固定句子长度,接受不同长度的句子做训练样本。
7.2 模型和核心思想(关键是要理解,为什么要这样设计模型结构)
7.2.1 设计模型需要考虑的因素,模型该具有什么样的性能:
1)用向量表示一个句子;
2)与word2vec一样,预测出来的词需要具有语义,根据上下文训练句子向量;
7.2.2 PV-DM模型结构(类似于CBOW)

在Doc2vec中,每一句话用唯一的向量来表示,用矩阵D的某一列来代表。每一个词也用唯一的向量来表示,用矩阵W的某一列来表示。每个句子都被映射到向量空间中,可以用矩阵的一列D来表示。每个单词同样本映射到向量空间中,用W的一列来表示。
每次从一句话中滑动采样固定长度的词,取其中一个词作为预测词,其他的作为输入词。输入词对应的词向量word vector和本句话对应的句子向量Paragraph vector作为输入层的输入,将本句话的向量和本次采样的词向量相加求平均或者累加构成一个新的向量X,进而使用这个向量预测此次窗口内的预测词。
句向量可以被认为是一个单词,它的作用相当于这个段落的主题。所以称为Distributed Memory Model of Paragraph Vecotrs(PV-DM)
总结doc2vec的过程, 主要有两步:
1)训练模型,在已知的训练数据中得到词向量, softmax的参数和,以及段落向量/句向量
2)推断过程(inference stage),对于新的段落,得到其向量表达。具体地,在矩阵D中添加更多的列,在固定W和softmax weights参数的情况下,利用上述方法进行训练,使用梯度下降法得到新的D,从而得到新段落的向量表达。
7.2.3 PV-DBOW模型(类似于skip-gram结构)

7.3 模型特点
无监督学习算法
用向量表示句子
学出来的向量可以通过计算距离来找sentences/paragraphs/documents之间的相似性,用于文本聚类,对于有标签的数据,还可以用监督学习的方法进行文本分类,例如情感分析问题。
---------------------------------------------------------------------------------------------
八、FastText
8.1 解决什么问题
是一个词向量计算和文本分类的工具,它的优点非常明显:在文本分类任务中,fastText(浅层网络)往往能取得和深度网络相媲美的精度,却在训练时间上比深度网络快许多数量级。
word2vec把语料库中的每个单词当成原子的,它忽略了单词内部的形态,比如:'apple'和'apples',两个单词都有较多公共字符,即它们的内部形态类似,但在传统的word2vec中,这种单词形态信息被丢失了(因为它们被转换成不同的id)。
8.2 模型和核心思想
8.2.1 模型结构,为什么这么设计
其中x1,x2,...,xn表示一个文本中的n-gram向量,每个特征是词向量的平均值。这个前文中提到的cbow相似,cbow用上下文去预测中心词,而此处用全部的n-gram去预测指定类别。
8.2.2 核心思想

8.2.3 层次softmax
fastText使用了层次softmax,对类别标签进行编码,能够极大地缩小模型预测目标的数量。
8.2.4 N-gram特征
在fasttext中,每个词被看做是n-gram字母串包
8.3 优点
1. 对于低频词生成的词向量效果更好,因为它们的n-gram可以和其它词共享;
2. 对于训练词库之外的单词,仍然可以构建它们的词向量。我们可以叠加它们的字符级n-gram向量。
8.4 fasttext与word2vec的区别
相似:
1.模型结构类似;
2.都采用了层次softmax进行优化提速;
不同处:
1. 模型的输出层:word2vec的输出层是一个term(单词),计算term的概率最大;而fattext的输出层对应的是分类的label,训练的vector不会被保留和使用;
2.模型的输入层:Word2vec的输入层,是context window的term;而fasttext对应的整个sentence的内容,包括term,也包括n-gram的内容;
两者本质的不同,体现在h-softmax的使用:
1. word2vec的目的是得到词向量,该词向量最终在输入层得到,输出层的h-softmax也会生成一系列的向量,但最终会抛弃不使用;
2. fasttext充分利用h-softmax的分类功能,遍历分类树的所有叶子节点,找到概率最大的label(Y一个或N个)
九、ELMO
十、GPT
十一、BERT
