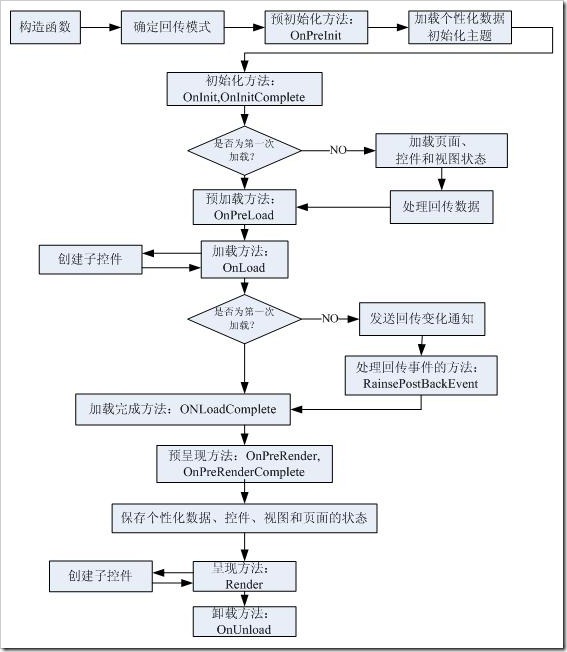
Oracle Group By 用法之 —— Having
转自:http://blog.csdn.net/zhaozhongju/archive/2009/05/13/4177047.aspx
客户需求分析:
笔者最近接到一家客户的一个需求。他们部署了一个ERP系统,现在采用的就是Oracle数据库。现在由于企业统计分析的需要,要实现如下的需求。
1、按月份来统计2009年第一季度每个供应商的采购金额。也就是说,在报表中要能够显示出2009年1月份、2月份、3月份供应商的采购金额合计,不需要明细。
2、显示的结果按年度、月份、供应商名字进行排序。

综合客户的要求,也就是说要实现如上这张报表。
PL/SQL语句解析:
select extract(YEAR FROM t.dateordered) AS 年度,extract(MONTH FROM t.dateordered) as 月份,
p.name as 供应商名字,sum(t.linenetamt) 合计
from c_orderline2 t
left join c_bpartner p on p.c_bpartner_id=t.c_bpartner_id
group by extract(YEAR FROM t.dateordered),extract(MONTH FROM t.dateordered),p.name
having extract(YEAR FROM t.dateordered)=2009 and extract(MONTH FROM t.dateordered) in (1,2,3)
order by p.name;
通过以上语句就可以实现企业如上的需求。在这个需求中,笔者主要用过Group By语句与Having语句来实现。这两个是Oralce数据库中PL/SQL语言中两个很重要的分组语句。利用这个两个语句可以实现一些复杂的统计功 能。对于Group By与Having语句的一些基本用法,笔者在这里不做过多描述。笔者这里想说的是,在使用这两个语句进行数据统计时需要注意的地方。在Oracle数据 库系统中,对于这两个统计子句做了比较严格的使用限制。数据库管理员必须对这些使用闲置铭记在心,否则的话很容易在统计的过程中遇到错误。具体来说,有如 下几个使用限制。
1、如果选择列表中包含有列、表达式或者分组函数,那么这些列或者表达式必须出现在Group By子句中,否则数据库会提示相关的错误信息。分组函数不用出现在Group By子句中。如上面这个例子,由于在数据库基础表中存储的是下订单的日期,如2009年4月15日。也就是说,年月日是存储在同一个字段中的。但是在统计 的时候,需要统计2009年1月、2月、3月的供应商采购金额。为此此时笔者先利用Extract函数从一个日期数据中抽取具体的年、月信息。这个是 Oracle数据库中一个很有用的日期函数。要是没有这个函数的话,笔者还需要通过字符串等处理函数来截取年月等信息。由于Extract是一个带函数的 表达式,为此其必须出现在Group By子句中。而且注意,笔者此时采用的是表达式本身,而不是其别名。也就是说,笔者没有采用group by年度,月份等表达方法。也就是说,在Group By子句中,必须采用表达式的全称,而不能够采用其别名。否则的话,数据库系统不会接受这个语句。数据库系统之所有要进行类似的控制,其背后藏有比较深层 次的原因。不过作为普通数据库管理员来说,不怎么用了解数据库设计背后的内容。只需要把这个规则记在心中即可。这个规则对于大部分数据库管理员来说,可能 会经常触犯他。为此笔者再次强调一遍,选择列表中如果包含有列、表达式时,这个列、表达式必须包含在Group By子句中。另外,如果采用了表达式的话,则数据库管理员即使在选择列表中采用了别名,但是在Group By子句中仍然必须采用表达式的完整表达方式,而不能够采用别名。
如果在一个查询语句中,同时含有Group By(分组语句)、Having(分组语句下的条件函数)、Order By(排序语句)三个共存的话,则需要注意他们有一定的书写顺序。通常情况下Order By排序语句必须放置在最后。如上面的案例中,笔者就把这个排序语句放在最末尾的地方。如果不这么处理的话,系统编译器是不会接受这个PL/SQL语句 的。另外需要注意的是,采用Group语句会自动对纪录进行排序。如上面的语句中,笔者并没有对年份、月度进行排序,而只是按供应商名称来进行排序。而现 实结果的话,却会自动按年度、月份的大小从小到大来进行排序。这主要因为Group By子句在统计之前,会先对记录按照Group By中的参数从左到右来进行排序,然后再进行统计。如此的话,最后显示的结果就是已经排过序来的结果。如果数据库管理员对于这个排序结果不满意的话,就需 要通过Order By子句再来对显示结果进行排序。不过这里需要注意的是,本身分组等子句就需要对纪录进行排序并进行一定的业务逻辑处理,此时会耗费比较多的数据库资源。 为此从数据库的性能考虑,在使用Order By排序子句对统计结果进行重新排序的时候,要慎重。如果想把某个字段当作第一顺序排序的话,则只需要把这个字段放置在分组语句中的第一个参数即可。如在 上面这个案例中,笔者完全可以通过group by p.name,extract(YEAR FROM t.dateordered),extract(MONTH FROM t.dateordered)这个分组语句来实现结果的排序,而可以不再使用Order By语句。为此只有在必要的情况下,才能够利用Order By子句。
Group By子句与Where子句是不兼容的。也就是说,在普通的Select等语句中(不含有Group By子句)时可以利用Where子句来过滤显示的结果。但是在上面的语句中,笔者却是使用Having语句来过滤显示结果的。这主要是因为Group By子句与Where子句是不兼容的。也就是说,当要显示分组显示结果时,数据库管理员必须要使用Having子句,而不能够在Where自居中使用分组 函数限制分组显示结果。如果数据库管理员在这里触犯这条原则话,那么数据库系统就会拒绝接受这条语句。数据库会提示错误信息,如“命令没有正确结束”等 等。另外Having语句主要用来限制分组统计结果,其跟Group By语句是双胞胎。即Having子句必须跟在Group By语句后面使用。其中Group By子句用户对查询结果进行分组统计,而Having子句则用于限制分组显示结果,即根据用户的要求来部分显示所需要的内容。他们是互相配合,分工合作。 可以说,如果没有Having语句的帮助,那么Group By语句会失色很多。另外,Having语句对于提高数据库与应用服务器的性能也有很大的关系。由于采用了Having语句来过滤显示的结果,那么其最终 符合条件的结果肯定比没有设置限制条件的要少的多。这也就意味着这个显示结果可以减少数据在网络中的传输,最好配上Having 条件过滤语句(虽然这并不属于强制限制)。如在在ERP系统中生成这张报表的时候,可以提示用户输入参数,如需要统计几几年几月份到几几年几月份的采购金 额。如果用户没有输入相关的数据的话,则其默认为最近一年的统计数据等等。这虽然是一个小小的技巧,但是在数据量比较多或者数据分组涉及到多张表的情况 下,可以非常有效的提高数据库与应用服务器的性能。这是一个强制的条件,数据库管理员必须无条件的遵守。
需要注意多列分组的顺序问题。group by p.name,extract(YEAR FROM t.dateordered),extract(MONTH FROM t.dateordered 与group by extract(YEAR FROM t.dateordered),extract(MONTH FROM t.dateordered ,p.name这两个分组语句有什么差别吗?如果光从结果上来说,是没有多大差异的。但是从其内部的处理机制上来说,有很大的差别。这主要涉及到多列分组 的问题。多列分组时指在Group By子句中使用两个或者两个以上的列生成分组统计结果。当进行多列分组时,汇集于多个列的不同值产生数据统计结果。如上面的例子中,数据库就会根据年份、 月份、供应商来生成统计结果。如果用前者的表达方式,则其先统计每个供应商的合计金额,在分类统计年、月的统计金额。简单的说,他们统计顺序不同,但是显 示结果相同。这也是第一点所说的,要把选择列表中的字段名、表达式等等全部放入到Group By子句中的原因。只有如此,Group By才会对这些字段进行分组统计。只有如此才能够保证,不会因为Group By子句中的参数顺序不同,而显示不同的统计结果。
可见Group By分组语句其使用规范要比普通的Select等查询语句要求严格的多。数据库管理员在使用Group语句进行数据分组统计时,一定要注意这些使用限制。否则的话在利用这个分组语句的时候,难免会磕磕碰碰的。