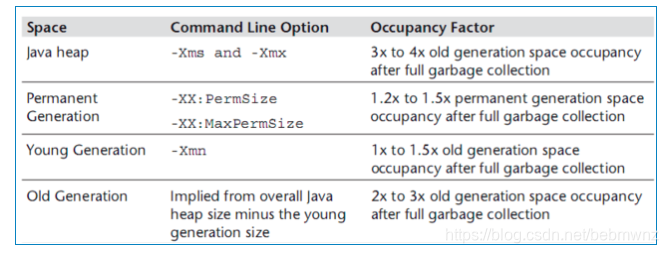
准备测试数据
dss,1,95
fda,1,80
ffd,1,95
cfe,2,74
gds,2,92
3dd,3,78
adf,3,45
asdf,3,55
ddd,3,99
gf,3,99use test;
create external table T2_TEMP
(name string,class string,sroce int)ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n' STORED AS TEXTFILE;load data local inpath '/tmp/data2.txt' overwrite into table T2_TEMP;1、over函数的写法:
over(partition by class order by sroce) 按照sroce排序进行累计,order by是个默认的开窗函数,按照class分区。
3、与over()函数结合的函数的介绍
(1)、查询每个班的第一名的成绩:rank()的使用(),如下
SELECT * FROM (
select t.name,t.class,t.sroce,rank() over(partition by t.class order by t.sroce desc) mm from T2_TEMP t
) table_1 where mm = 1;得到的结果是:
dss 1 95 1
ffd 1 95 1
gds 2 92 1
gf 3 99 1
ddd 3 99 1注意:在求第一名成绩的时候,不能用row_number(),因为如果同班有两个并列第一,row_number()只返回一个结果。
SELECT * FROM (
select t.name,t.class,t.sroce,row_number() over(partition by t.class order by t.sroce desc) mm from T2_TEMP t
) table_1 where mm = 1;结果为:
dss 1 95 1
gfs 2 92 1
ddd 3 99 1 可以看出,本来第一名是两个人的并列,row_number() 结果只显示了一个。
(2)、rank()和dense_rank()可以将所有的都查找出来,rank可以将并列第一名的都查找出来;rank()和dense_rank()区别:rank()是跳跃排序,有两个第二名时接下来就是第四名。
rank()求班级成绩排名:
select t.name,t.class,t.sroce,rank() over(partition by t.class order by t.sroce desc) mm from T2_TEMP t;查询结果:
dss 1 95 1
ffd 1 95 1
fda 1 80 3
gds 2 92 1
cfe 2 74 2
gf 3 99 1
ddd 3 99 1
3dd 3 78 3
asdf 3 55 4
adf 3 45 5
dense_rank()l是连续排序,有两个第二名时仍然跟着第三名
select t.name,t.class,t.sroce,dense_rank() over(partition by t.class order by t.sroce desc) mm from T2_TEMP t;查询结果:
dss 1 95 1
ffd 1 95 1
fda 1 80 2
gds 2 92 1
cfe 2 74 2
gf 3 99 1
ddd 3 99 1
3dd 3 78 2
asdf 3 55 3
adf 3 45 4
3、sum()over()的使用
根据班级进行分数求和
select t.name,t.class,t.sroce,sum(t.sroce) over(partition by t.class order by t.sroce desc) mm from T2_TEMP t;dss 1 95 190 --由于两个95都是第一名,所以累加时是两个第一名的相加
ffd 1 95 190
fda 1 80 270 --第一名加上第二名的
gds 2 92 92
cfe 2 74 166
gf 3 99 198
ddd 3 99 198
3dd 3 78 276
asdf 3 55 331
adf 3 45 376
4、first_value() over()和last_value() over()的使用
select t.name,t.class,t.sroce,first_value(t.sroce) over(partition by t.class order by t.sroce desc) mm from T2_TEMP t;select t.name,t.class,t.sroce,last_value(t.sroce) over(partition by t.class order by t.sroce desc) mm from T2_TEMP t;分别求出第一个和最后一个成绩。
5、sum() over()的使用,求出班级的总分。
select t.name,t.class,t.sroce,sum(t.sroce) over(partition by t.class order by t.sroce desc) mm from T2_TEMP t;
下面还有很多用法,就不一一列举了,简单介绍一下,和上面用法类似:
count() over(partition by ... order by ...):求分组后的总数。
max() over(partition by ... order by ...):求分组后的最大值。
min() over(partition by ... order by ...):求分组后的最小值。
avg() over(partition by ... order by ...):求分组后的平均值。
lag() over(partition by ... order by ...):取出前n行数据。
lead() over(partition by ... order by ...):取出后n行数据。
ratio_to_report() over(partition by ... order by ...):Ratio_to_report() 括号中就是分子,over() 括号中就是分母。
percent_rank() over(partition by ... order by ...):
6、over partition by与group by的区别:
group by是对检索结果的保留行进行单纯分组,一般和聚合函数一起使用例如max、min、sum、avg、count等一块用。partition by虽然也具有分组功能,但同时也具有其他的高级功能。
![[编写高质量代码:改善java程序的151个建议]建议83 推荐使用枚举定义常量](https://img-blog.csdnimg.cn/2022010617000364850.png)